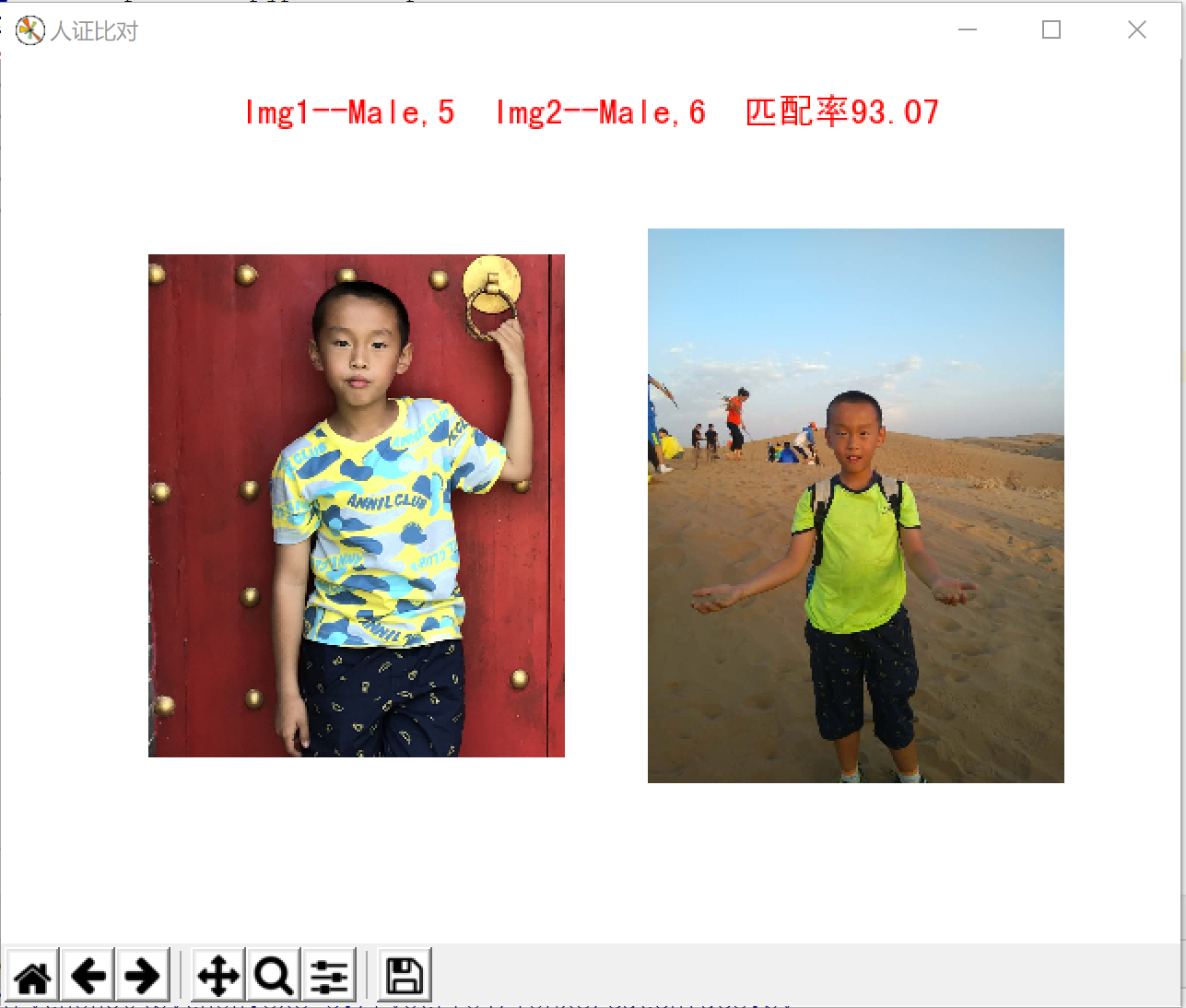
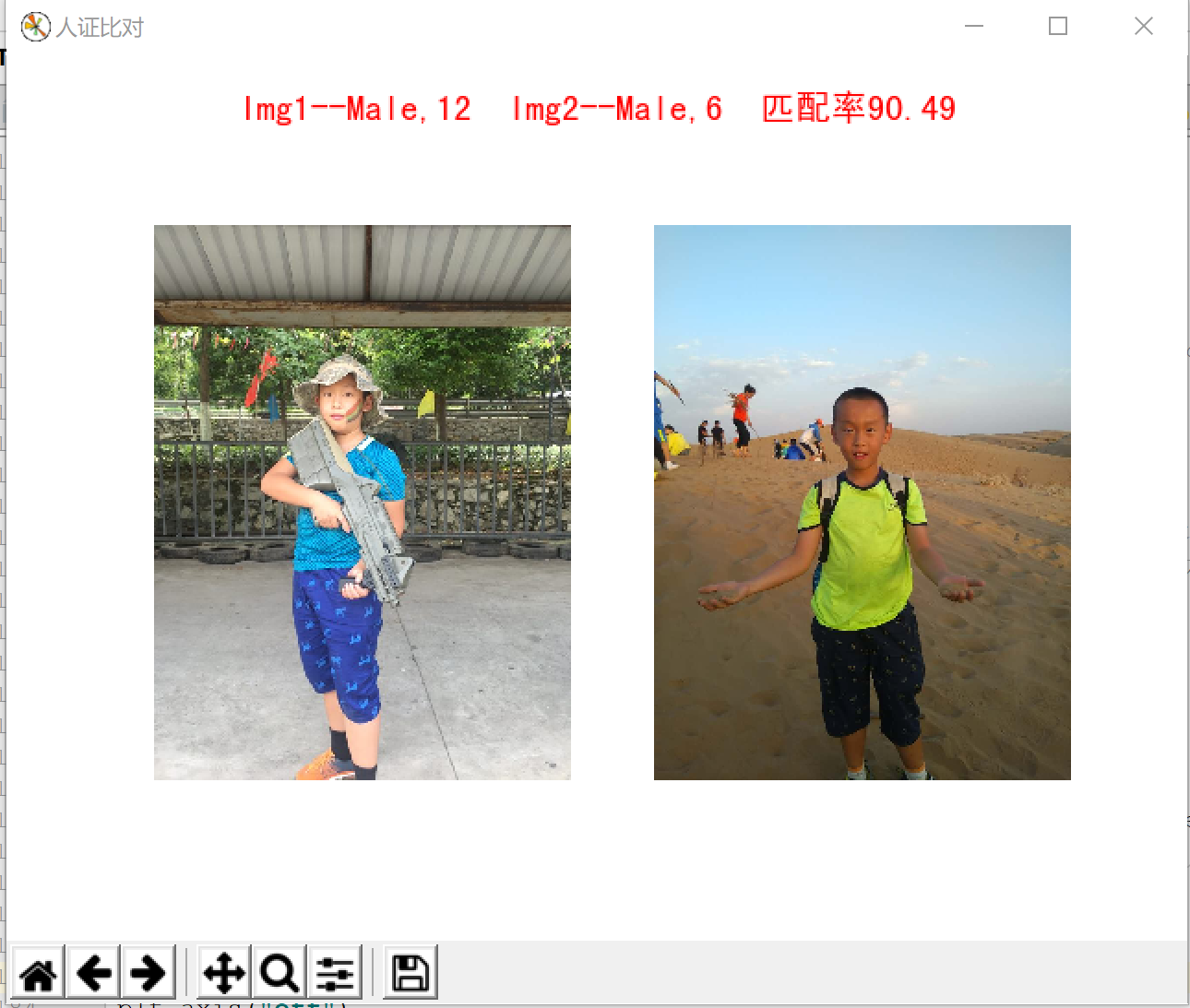
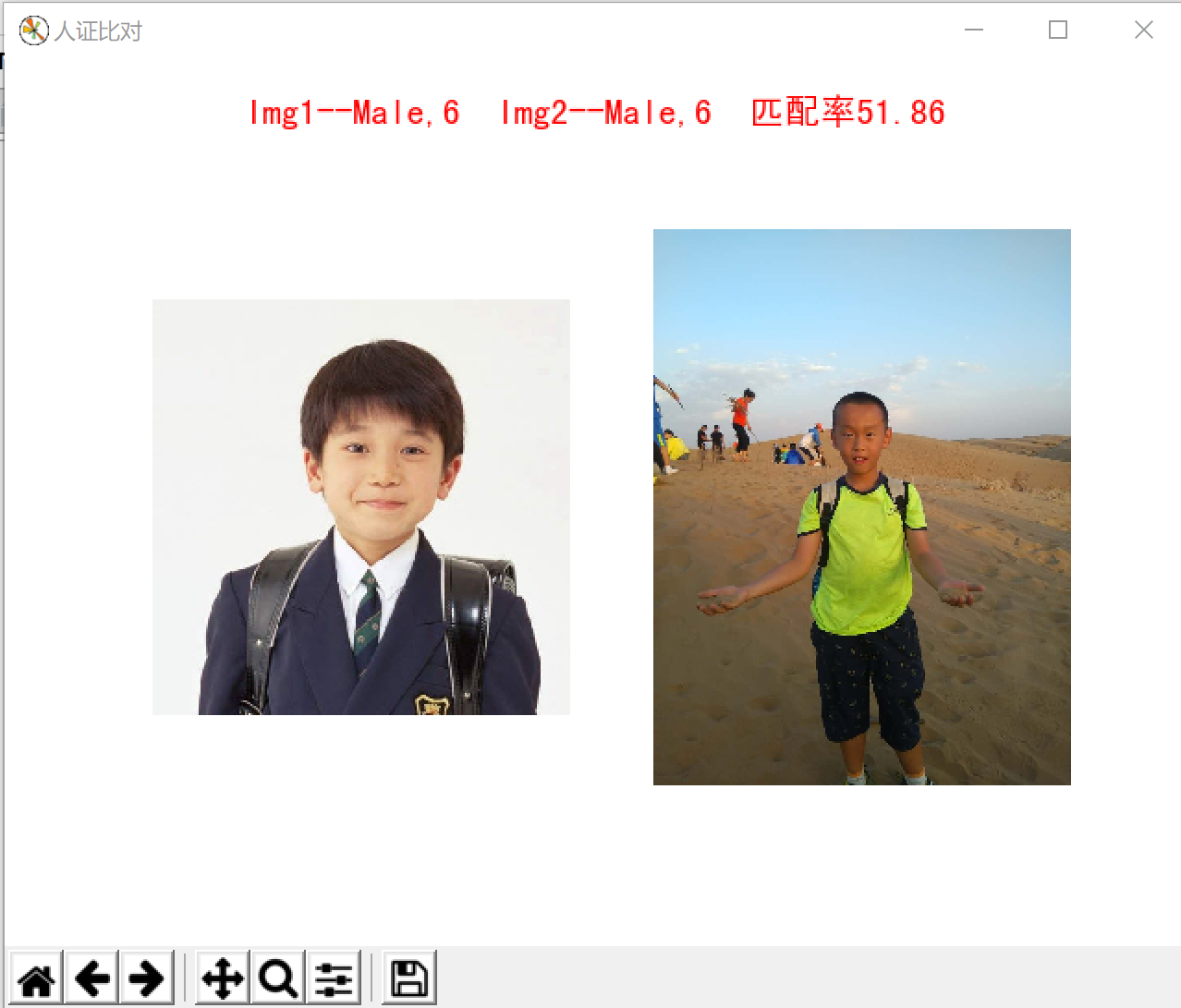
利用face++的API对两张图片进行人脸检测和人脸比对
__author__ = "MrBean"
import requests#网络访问控件
from json import JSONDecoder#互联网数据交换标准格式
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from PIL import Image
# card_image_file = 'C:\\Users\JustDoIt\Pictures\mmexport1562819342929.jpg'
card_image_file = 'C:\\Users\JustDoIt\Pictures\dudu2.jpg'
people_image_file = 'C:\\Users\JustDoIt\Pictures\mmexport1499863959380.jpg'
# 读取图片
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
card_image = get_file_content(card_image_file)
people_image = get_file_content(people_image_file)
"""
#利用face++提供的API
"""
key ="**************"#开发人员识别码
secret ="***************"
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
myfont = fm.FontProperties(fname='SimHei.ttf') #用来正常显示中文
###人脸检测
http_url ="https://api-cn.faceplusplus.com/facepp/v3/detect"#face++apiDETECT模块
attri="gender,age"#指定返回的属性变量(性别,年龄)
"""
# attributes 中包含的元素说明
# gender String
# 性别分析结果。返回值为:
# Male 男性
# Female 女性
# age Int
# 年龄分析结果。返回值为一个非负整数。
# headpose Object
# 人脸姿势分析结果。返回值包含以下属性,每个属性的值为一个 [-180, 180] 的浮点数,小数点后 6 位有效数字。单位为角度。
# pitch_angle:抬头
# roll_angle:旋转(平面旋转)
# yaw_angle:摇头
# blur Object
# 人脸模糊分析结果。返回值包含以下属性:
# blurness:人脸模糊分析结果。
# 每个属性都包含以下字段:
# value 的值为是一个浮点数,范围 [0,100],小数点后 3 位有效数字。值越大,越模糊。
# threshold 表示人脸模糊度是否影响辨识的阈值。
# eyestatus Object
# 眼睛状态信息。返回值包含以下属性:
# left_eye_status:左眼的状态
# right_eye_status:右眼的状态
# 每个属性都包含以下字段。每个字段的值都是一个浮点数,范围 [0,100],小数点后 3 位有效数字。字段值的总和等于 100。
# occlusion:眼睛被遮挡的置信度
# no_glass_eye_open:不戴眼镜且睁眼的置信度
# normal_glass_eye_close:佩戴普通眼镜且闭眼的置信度
# normal_glass_eye_open:佩戴普通眼镜且睁眼的置信度
# dark_glasses:佩戴墨镜的置信度
# no_glass_eye_close:不戴眼镜且闭眼的置信度
# emotion Object
# 情绪识别结果。返回值包含以下字段。每个字段的值都是一个浮点数,范围 [0,100],小数点后 3 位有效数字。
# 每个字段的返回值越大,则该字段代表的状态的置信度越高。字段值的总和等于 100。
# anger:愤怒
# disgust:厌恶
# fear:恐惧
# happiness:高兴
# neutral:平静
# sadness:伤心
# surprise:惊讶
# facequality Object
# 人脸质量判断结果。返回值包含以下属性:
# value:值为人脸的质量判断的分数,是一个浮点数,范围 [0,100],小数点后 3 位有效数字。
# threshold:表示人脸质量基本合格的一个阈值,超过该阈值的人脸适合用于人脸比对。
# ethnicity String
# 人种分析结果,返回值为:
# Asian 亚洲人
# White 白人
# Black 黑人
# beauty Object
# 颜值识别结果。返回值包含以下两个字段。每个字段的值是一个浮点数,范围 [0,100],小数点后 3 位有效数字。
# male_score:男性认为的此人脸颜值分数。值越大,颜值越高。
# female_score:女性认为的此人脸颜值分数。值越大,颜值越高。
# mouthstatus Object
# 嘴部状态信息,包括以下字段。每个字段的值都是一个浮点数,范围 [0,100],小数点后 3 位有效数字。字段值的总和等于 100。
# surgical_mask_or_respirator:嘴部被医用口罩或呼吸面罩遮挡的置信度
# other_occlusion:嘴部被其他物体遮挡的置信度
# close:嘴部没有遮挡且闭上的置信度
# open:嘴部没有遮挡且张开的置信度
# eyegaze Object
# 眼球位置与视线方向信息。返回值包括以下属性:
# left_eye_gaze:左眼的位置与视线状态
# right_eye_gaze:右眼的位置与视线状态
# 每个属性都包括以下字段,每个字段的值都是一个浮点数,小数点后 3 位有效数字。
# position_x_coordinate: 眼球中心位置的 X 轴坐标。
# position_y_coordinate: 眼球中心位置的 Y 轴坐标。
# vector_x_component: 眼球视线方向向量的 X 轴分量。
# vector_y_component: 眼球视线方向向量的 Y 轴分量。
# vector_z_component: 眼球视线方向向量的 Z 轴分量。
# skinstatus Object
# 面部特征识别结果,包括以下字段。每个字段的值都是一个浮点数,范围 [0,100],小数点后 3 位有效数字。每个字段的返回值越大,则该字段代表的状态的置信度越高。
# health:健康
# stain:色斑
# acne:青春痘
# dark_circle:黑眼圈
"""
data = {"api_key":key, "api_secret": secret, "return_attributes":attri}
# data = {"api_key":key, "api_secret": secret}
#数据格式化准备发送到face,词典格式json
files = {"image_file":card_image}#准备打开
response = requests.post(http_url, data=data, files=files)#用post方式(还有get)发送数据到网站
req_con = response.content.decode('utf-8')#网页解码
req_dict = JSONDecoder().decode(req_con)#把json解码成python词典格式
gender1 = req_dict["faces"][0]["attributes"]["gender"]["value"]
age1 = req_dict["faces"][0]["attributes"]["age"]["value"]
print(req_dict)
files = {"image_file":people_image}#准备打开
response = requests.post(http_url, data=data, files=files)#用post方式(还有get)发送数据到网站
req_con = response.content.decode('utf-8')#网页解码
req_dict = JSONDecoder().decode(req_con)#把json解码成python词典格式
gender2 = req_dict["faces"][0]["attributes"]["gender"]["value"]
age2 = req_dict["faces"][0]["attributes"]["age"]["value"]
print(req_dict)
####人脸比对
title = "人证比对"
http_url = "https://api-cn.faceplusplus.com/facepp/v3/compare" # face++apiDETECT模块
data = {"api_key": key, "api_secret": secret}
#对证件图片进行处理
# 数据格式化准备发送到face,词典格式json
files = {"image_file1":card_image,"image_file2":people_image} # 准备打开
response = requests.post(http_url, data=data, files=files) # 用post方式(还有get)发送数据到网站
req_con = response.content.decode('utf-8') # 网页解码
req_dict = JSONDecoder().decode(req_con) # 把json解码成python词典格式
print(req_dict)
comp_result = req_dict["confidence"]
print(comp_result)
fig = plt.figure(title)
sup_title = "Img1--%s,%d" % (gender1,age1) + " Img2--%s,%d" % (gender2,age2) + " 匹配率%.2f"%(comp_result)
plt.suptitle(sup_title,fontproperties = myfont, fontsize = 14, color = 'red', y = 0.96)
plt.ion()
ax = fig.add_subplot(1, 2, 1)
# plt.imshow(card_crop_image)
plt.imshow(Image.open(card_image_file))
plt.axis("off")
ax = fig.add_subplot(1, 2, 2)
plt.imshow(Image.open(people_image_file))
plt.axis("off")
res_image_file = card_image_file.replace(".jpg","_res.jpg")
plt.savefig(res_image_file) #保存比对结果图片
plt.pause(2) # 显示秒数
plt.close()
运行结果截图